
Enabling easy and reproducible access to datasets is the primary purpose of the chronosphere. But what do we mean by accessing a dataset?
Structure
The structure of the chronosphere was designed from the application point of view: how researchers would like to use data that is already shared. Identifiers were desined to be both memorable, and machine-readable. These are organized in a hierarchy that can be thought of as coordinates to find a specific data item.
1. Data Items
Items represent the lowest-level entities of the chronosphere framework. A data item is a programming object-level representation of a dataset with a definite structure, i.e. a programming class. Users (i.e. researchers or analysts) interact with items.
Items are imported by a client, which executes some code that instantiates the object. They are typically read in from data files and/or structured by some code that is assigned to item. A programming class and some code is always mapped to an item, and data files can be.
The data structures of the chronosphere.
2. Data Products
Although items represent the basic technical units, the fundamental semantic entity of the chronosphere is the data product. The product represents colloquial “data” that represent a certain amount of information: it does not matter whether a .csv or .parquet file is used to store the same data or whether it is present in the form of a Pandas.DataFrame or an R data.table. If the content is the same, all represent the same data product.
Data products have well-defined boundaries in terms of content, size and meaning. The abtract data products always manifest as an item.
Represent the state-of-the-art at a given point in time and can always be assigned to a date of finalization publication, and or a version identifier. They can also be altered in slight ways fo fulfil a specific function (e.g. resolution).
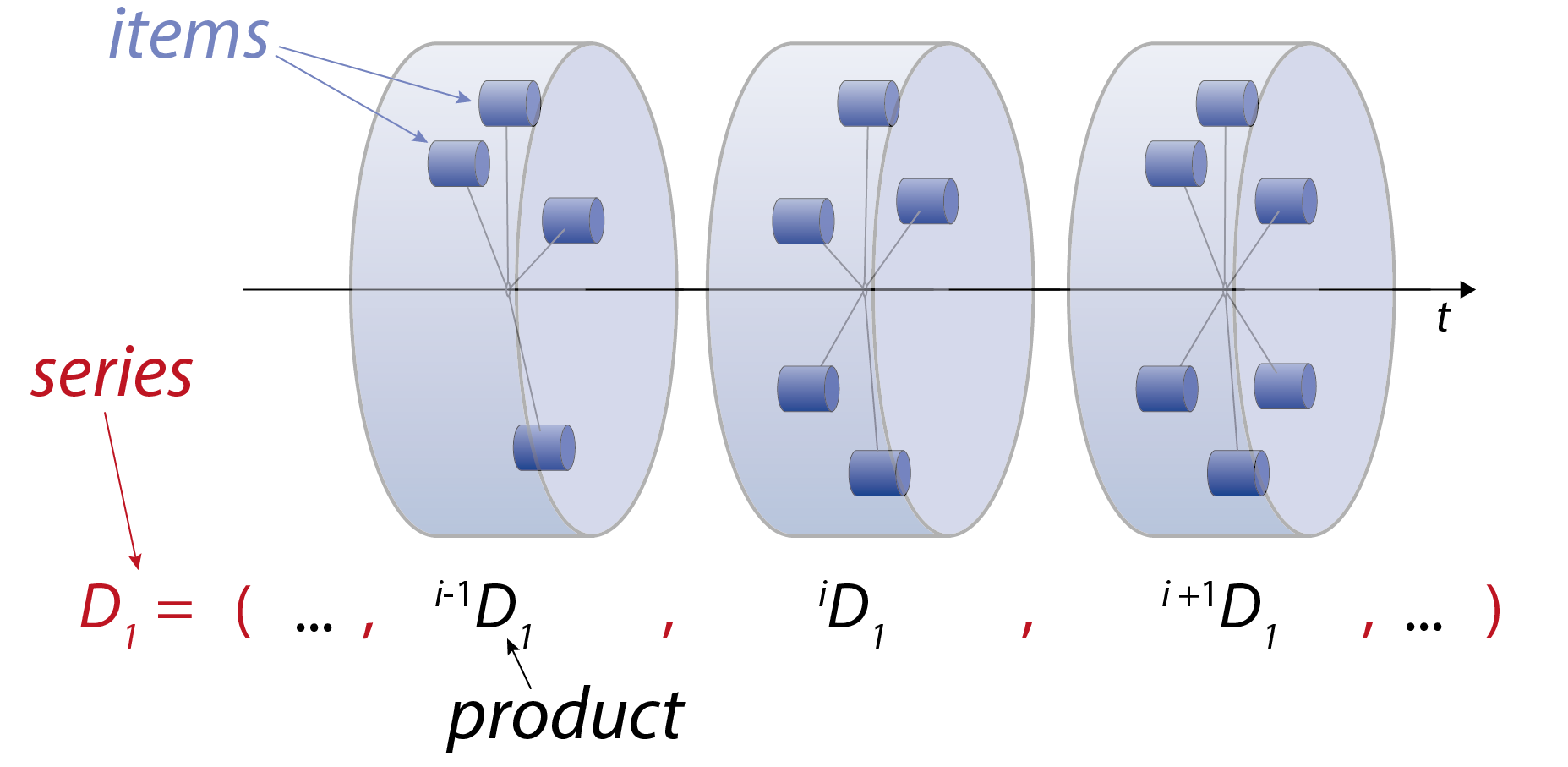
3. Data Series
Series are a set of products that are derived using specific rules - in many cases with the same programming pipeline, which applied to an updated set of data to create a specific data product. Examples include database API calls that compile the same table structure from the most up-to-date state of a database (such as series from the Paleobiology Database), and named data products that are released at either regular or irregular intervals. Products within the same series are expected to have the same overall structure, but different content.
The definition of series has been one of the primary goals of the chronosphere: it allows the quick substitution of differently-versioned products of the same series, which is a technical prerequisite to tracing scientific results through time in the face of changing data.
4. Data Sources
Sources are either formal or informal entites that can be tied data structures. This level of hierarchy helps with organizing information and finding information that can be tied to an organization, a database or a scientific paper.
Example
Items can be located by referring to its coordinates - usually from top- to lower-level of hierarchy. Shorthand code are used to identify the levels.
| Coordinate | code | example |
|---|---|---|
| Source | src |
"paleomap" |
| Series | ser |
"dem" |
| Product | ver + res |
ver="v24221",res=0.1 |
| Item | class + ext |
class="RasterArray", ext="nc" |
All these define a very specicific specific data item (PaleoDEMs of C. Scotese) that can be instantiated locally in R with this chunk of code :
library(chronosphere)
paleodems <- fetch(src="paloemap", ser="dem", ver="v24221",res=0.1) # class and ext are defaults
You can find the automatically prepared page for this data series here. Data items will be documented on this website, but this is still under construction. In the meantime, use the R package’s datasets() function to access available data.